
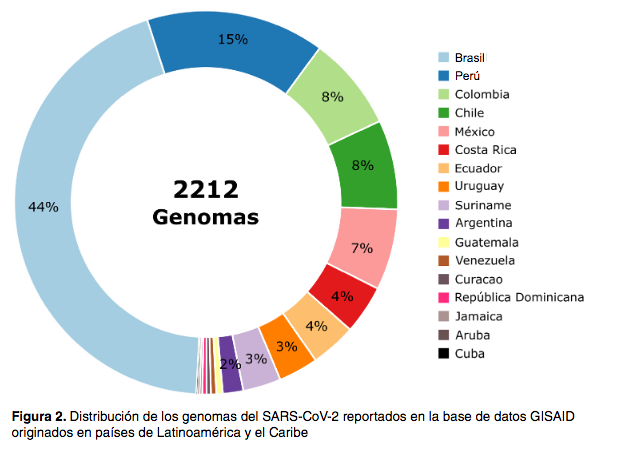
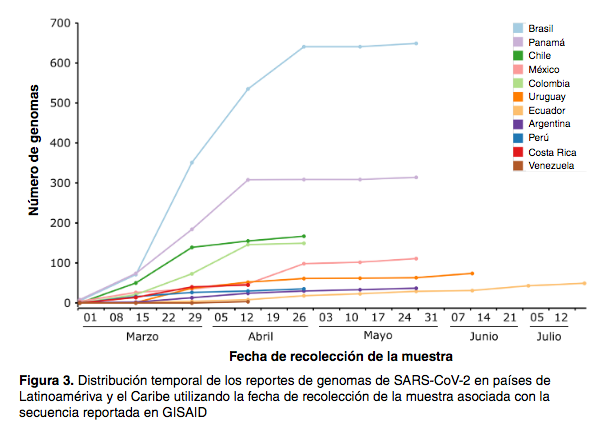
La pandemia de COVID-19 causada por el SARS-CoV-2 es un problema de salud pública sin precedentes en los últimos 100 años, así como la respuesta centrada en la caracterización genómica del SARS-CoV-2 prácticamente en todas las regiones del planeta. Esta pandemia surgió durante la era de la epidemiología genómica impulsada por los continuos avances en la secuenciación de próxima generación. Desde su reciente aparición, la epidemiología genómica permitió la identificación precisa de nuevos linajes o especies de agentes patógenos y la reconstrucción de su variabilidad genética en tiempo real, lo que se hizo evidente en los brotes de influenza H1N1, MERS y SARS. Sin embargo, la escala global y descontrolada de esta pandemia ha generado una situación que obligó a utilizar de forma masiva herramientas de la epidemiología genómica como la rápida identificación del SARS-CoV-2 y el registro de nuevos linajes y su vigilancia activa en todo el mundo. Antes de la pandemia de COVID-19 la disponibilidad de datos genómicos de agentes patógenos circulantes en varios países de Latinoamérica y el Caribe era escasa o nula. Con la llegada del SARS-CoV-2 dicha situación cambió significativamente, aunque la cantidad de información disponible sigue siendo escasa y, en países como Colombia, Brasil, Argentina y Chile, la información genómica del SARS-CoV-2 provino principalmente de grupos de investigación en epidemiología genómica más que como producto de una política o programa de vigilancia en salud pública. Ello evidencia la necesidad de establecer políticas de salud pública orientadas a la implementación de la epidemiología genómica como herramienta para fortalecer los sistemas de vigilancia y alerta temprana frente a amenazas para la salud pública en la región.
Palabras clave: infecciones por coronavirus; síndrome respiratorio agudo grave; virus del SRAS; secuenciación de nucleótidos de alto rendimiento; vigilancia epidemiológica; políticas en salud pública.
Implementación y aplicaciones de la secuenciación del SARS-CoV-2 en Colombia
Las primeras diez secuencias del SARS-CoV-2 en Colombia se obtuvieron de muestras captadas en ocho ciudades del país (Cartagena, Santa Marta, Ibagué, Bogotá, Medellín, Cali, Palmira y Popayán), donde se confirmaron los primeros casos de COVID-19 importados desde Europa, como parte de la vigilancia virológica de rutina liderada por el Instituto Nacional de Salud de Colombia. La disponibilidad de protocolos en la web específicos para la secuenciación del SARS-CoV-2 basada en amplicones de PCR permitió que los investigadores del Instituto Nacional de Salud, en cooperación con investigadores del Instituto Alexander von Humboldt y la Universidad Cooperativa de Colombia, los aplicaran en la secuenciación del nuevo coronavirus e implementaran la tecnología de secuenciación de Oxford Nanopore–MinION en tan solo tres semanas a partir del primer caso confirmado de COVID-19 en el país, con lo cual las primeras secuencias del SARS-CoV-2 quedaron disponibles en el repositorio de secuencias genómicas del nuevo coronavirus, GISAID.
Simultáneamente, investigadores de la Universidad del Valle y del Centro Internacional de Agricultura Tropical demostraron la capacidad instalada para secuenciar el SARS-CoV-2 a partir de muestras captadas localmente. Así, las primeras secuencias del SARS-CoV-2 en Colombia evidenciaron la variabilidad genética en diferentes posiciones nucleotídicas de los sitios genómicos del virus, usados en las pruebas moleculares (rRT-PCR) para el diagnóstico de la COVID-19 y disponibles en el sitio web de la Organización Mundial de la Salud (OMS). Ello demostró que la acumulación de mutaciones en el genoma viral es relativamente frecuente y, en consecuencia, es importante evaluar periódicamente los sitios blanco para el diagnóstico molecular usando la información de las secuencias disponibles para verificar mediante simulación por computadorsu potencial efecto en el desempeño de las pruebas.
En los meses siguientes otros estudios corroboraron esta información a la luz de nuevas secuencias del SARS-CoV-2 reportadas en GISAID por investigadores colombianos, las cuales se sumaron a las reportadas por otros países de la región, incluidos Brasil, Chile, Ecuador, Uruguay, Perú y Argentina, lo que demuestra el alcance de estos hallazgos en el territorio sudamericano, así como en las pruebas de inmunodiagnóstico basadas en anticuerpos contra las proteínas N y S del SARS-CoV-2. Además, la capacidad de secuenciación instalada del Instituto Nacional de Salud permitió clasificar el primer aislamiento del SARS-CoV-2 colombiano (obtenido por investigadores de la Universidad de Antioquia) en el linaje B.1.5, uno de los más prevalentes en el país.
Esta información resulta crucial para determinar las cepas del virus que se emplearán en pruebas in vitro para la evaluación de compuestos terapéuticos o desinfectantes. Por último, las secuencias del SARS-CoV-2 identificadas durante la fase temprana de la pandemia de COVID-19 en Colombia aportaron datos moleculares para respaldar la información epidemiológica relativa a la proporción de casos importados de Europa y América y la reconstrucción de cadenas de transmisión viral, así como para estimar la variabilidad genética de SARS-CoV-2 en el país, traducida en la identificación de 12 sub linajes del SARS-CoV-2 importados en un transcurso de dos meses desde la confirmación del primer caso.
Conclusiones y perspectivas
Es una necesidad urgente fortalecer la cooperación entre los laboratorios de salud pública de Latinoamérica y el Caribe para facilitar la transferencia tecnológica, el entrenamiento del personal y la adquisición de recursos para insumos, infraestructura y mejoramiento de la capacidad instalada en el laboratorio, entre otros. Esto permitirá establecer consensos sobre la vigilancia genómica en la región para los sistemas de alerta temprana frente al SARS-CoV-2 y otros agentes patógenos que amenacen la salud pública. Ello debe acompañarse de políticas regionales de asignación de recursos financieros para el mejoramiento de la capacidad instalada en los laboratorios, la adquisición de insumos y equipos y los programas de entrenamiento de profesionales en análisis de datos, lo que permitirá fortalecer los sistemas de vigilancia genómica y de alerta temprana frente a amenazas para la salud pública.