
Lluis Montoliu, Resucitando proteínas CRISPR-Cas ancestrales de hace millones de años – Gen-Ética (naukas.com)
Recopilado por Carlos Cabrera Lozada. Miembro Correspondiente Nacional, ANM puesto 16. ORCID: 0000-0002-3133-5183. 07/01/2022
Un estudio colaborativo, liderado por Raúl Pérez-Jiménez (CICnanoGUNE, San Sebastián), con la participación de los laboratorios de Francis Mojica (Universidad de Alicante), de mi laboratorio en el CNB-CSIC y de otros colaboradores, acaba de publicarse en la revista Nature Microbiology. En este trabajo demostramos que es posible resucitar proteínas Cas9 que podrían haber existido en bacterias hace muchos millones de años, a la vez que comprobamos que funcionan como herramientas de edición genética en células humanas.
Es indudable que las herramientas CRISPR-Cas nos han cambiado la vida a muchos investigadores. Estos sistemas CRISPR-Cas fueron originalmente descritos por Francis Mojica como parte de un sistema defensa adaptativo que usan las bacterias para defenderse de los virus (los bacteriófagos) que las atacan. Años después, dos investigadoras, Emmanuelle Charpentier y Jennifer Doudna, las convirtieron en herramientas de edición genética, capaces de inactivar o inducir la edición dirigida de cualquier gen de cualquier organismo. Estas investigadoras acabaron recibiendo un merecido Premio Nobel de Química en 2020. El resto es ya historia de la biología.
La inmensa mayoría de laboratorios en el mundo seguimos usando el sistema CRISPR-Cas9 de la bacteria Streptococcus pyogenes (SpCas9), que fue el primer sistema completo descrito por Charpentier y Doudna en su artículo en la revista Science publicado en junio de 2012. Añgunos años después Feng Zhang describió una nucleasa Cas9 algo más pequeña, derivada de un sistema CRISPR-Cas9 de Staphylococcus aureus (SaCas9). Esta nucleasa SaCas9 era más pequeña y por ello podía incluirse todo el sistema CRISPR-Cas correspondiente en una sola partícula viral de virus adenoasosiados (AAV), en lugar de tener que usar dos, como es el caso de la SpCas9, pues es necesario usar otro virus para incluir la guía ARN que dirija el corte y el ADN molde que se quiera utilizar para recombinar el gen deseado tras el corte generado por la nucleasa.
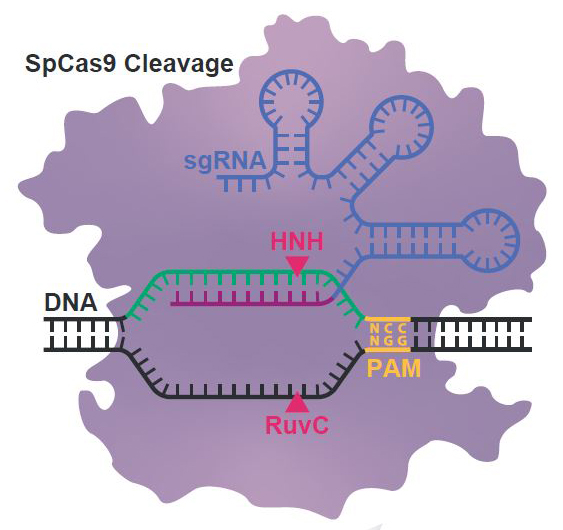
Sin embargo, tanto Streptococcus pyogenes como Staphilococcus aureus son bacterias patógenas para los seres humanos, causantes habituales de infecciones por todo el cuerpo (S. aureus) o de otitis y laringitis (S. pyogenes), y, por ello, nuestro sistema inmunitario tiene ya anticuerpos contra ellas, y contra todos sus componentes, incluidas las proteínas SpCas9 y SaCas9. De esto se dio cuenta el investigador Matthew Porteus (Stanford University, CA, EE.UU.), demostrando que la mayoría de personas tenemos anticuerpos contra estas proteínas Cas9 de estas dos bacterias. Este contratiempo inesperado acabó siendo publicado en la revista Nature Medicine. Lógicamente no quieres usar como proteína terapéutica algo contra lo cual tu sistema inmunitario reaccionará atacándolo. Por eso se han intentado encontrar muchas otras nucleasas Cas9 y otras Cas derivadas de otras bacterias, alejadas de cualquier interacción con los seres humanos. El número de sistemas CRISPR-Cas9 descritos ha aumentado rápidamente, así como la descripción de proteínas Cas a partir de metagenomas, a partir de predicciones bioinformáticas, o de bacterias y arqueas de los lugares más recónditos y extremos del planeta, como el desierto de Atacama.
Una alternativa a buscar nuevas Cas9 en bacterias que habitan los rincones más inóspitos de la Tierra es buscarlas no en el espacio, sino en el tiempo, intentando resucitar proteínas ancestrales Cas que debieron existir hace muchos millones de años. El principal problema de esta aproximación es la falta de registro fósil ni de restos orgánicos a partir de los cuales obtener ADN. Hace pocas semanas se publicó el ADN más antiguo recuperado de unos minerales de Groenlandia que tenía unos 2 millones de años de antiguedad. Esto puede parece mucho, pero, a nivel geológico, teniendo en cuenta que nuestro planeta se cree que tiene unos 4.500 millones de años de antiguedad, es una nimiedad.
Hace faltar ir más allá de 2 millones de años, mucho más. ¿Cómo lo hacemos? Esto es lo que hace la paleoenzimología. Reconstruir secuencias de proteínas ancestrales que debieron existir en organismos ya extintos a partir de las secuencias de estas proteínas en un determinado grupo de organismos actuales y de sus relaciones filogenéticas. Aplicando técnicas estadísticas de máxima verosimilitud y con la suficiente potencia computacional pueden inferirse las secuencias ancestrales más probables, que podrían haber existido y que son compatibles y permiten explicar la diversidad actual de secuencias. Calibrando el análisis con una línea de tiempo puede deducirse la edad en la que se situan los nodos de proteínas ancestrales que dieron lugar a diferentes grupos de proteínas Cas9 actuales.

Siguiendo esta estrategia el equipo de Raúl Pérez-Jiménez obtuvo las secuencias de proteínas Cas9 de un conjunto de 59 bacterias actuales, evolutivamente relacionadas, en mayor (del genéro Streptococcus) o menor medida (del género Enterococcus, Clostridium y Bifidobacterium, entre otras) y puso a trabajar un potente ordenador con un algoritmo de máxima verosimilitud para inferir las proteínas Cas9 ancestrales más probables que podrían haber existido y haber dado lugar a la diversidad de proteínas Cas9 actuales. Calibrando la ubicación de los nodos con una línea temporal pudieron establecer cinco proteínas Cas9 ancestrales, llamadas: PDCA, PCA, SCA, BCA y FCA que pudieron existir hace 37, 137, 200, 1.000 y 2.600 millones de años, respectivamente. Estas edades exceden, en mucho, la posibilidad de encontrar restos de cualquier ADN antiguo, actualmente limitado hasta los 2 millones de años. Las proteínas Cas9 ancestrales resultantes se parecen a la SpCas9 actual entre un 56% (las más antiguas) y un 93% (las más modernas) de identidad molecular.
Para ubicar mentalmente las edades estimadas que tienen estas nucleasas Cas ancestrales resucitadas informáticamente recordad que: la Tierra tiene una edad de ~4.500 millones de años; que las evidencias más antiguas de células procariotas son de hace ~3.500 millones de años; que las células eucariotas (con núcleo, producto de la fusión de varias bacterias según la teoría endosimbionte propuesta por Lynn Margulis) aparecieron hace ~1.850 millones de años; que la explosión Cámbrica que dio lugar a la mayoría de grupos de animales que existen hoy en día tuvo lugar hace ~580 millones de años; que el Braquiosaurio (uno de los dinosaurios más grandes que jamás existieron, el primero que sale en la película Parque Jurásico) se extinguió hace ~150 millones de años; y que el resto de dinosaurios se extinguieron hace 65 millones de años, exceptuando los que dieron lugar a las aves actuales.

Una vez obtenidas las secuencias de las proteínas Cas ancestrales se sintetizaron las secuencias correspondientes de ADN que las codificaban, usando codones optimizados para la bacteria Escherichia coli, para poder proceder a obtener y purificar proteínas para hacer los experimentos in vitro.
La caracterización funcional de las cinco proteínas Cas ancestrales resucitadas se hizo a dos niveles: in vitro, en el laboratorio, e in vivo, en células humanas. En primer lugar se constató que a medida que nos alejamos del momento actual, las Cas ancestrales más antiguas tienen mayor tendencia a tener una actividad de corte de una de las dos cadenas del ADN (actividad nickasa) frente a una actividad de corte de las dos cadenas del ADN, como tienen las Cas9 actuales. En segundo lugar se detectó actividad de corte de ADN de cadena sencilla y de ARN (que también es de cadena simple) también en las Cas ancestrales más antiguas, mientras que las Cas ancestrales más «modernas» mostraban preferentemente una actividad de corte de ADN de doble cadena. Todo ello guiado por una molécula de ARN guía derivada de la estructura que conocemos para la SpCas9 actual, que probablemente no esté optimizada para todas estas Cas ancestrales, a pesar de ser reconocida aparentemente, con mayor o menor acierto, por todas ellas. Estas observaciones encajan con un mundo original esencialmente basado en moléculas de ADN y ARN monocatenarias, un mundo ARN que es una de las hipótesis más aceptadas del origen del material genético en los seres vivos. De ahí que las Cas ancestrales sea lógico que prefieran cortar moléculas de cadena sencilla.
La especificidad de las diferentes Cas ancestrales se evaluó investigando sus requerimientos de la secuencia PAM (Protospacer Adjacent Motif), que es otro de los hallazgos y nombres que propuso Francis Mojica, y que las bacterias usan para diferenciar entre la secuencia a cortar presente en el genoma del virus de la misma secuencia insertada en el genoma bacteriano, evitando suicidarse, degradando su propio genoma. La SpCas9 actual necesita tener la serie de tres nucleótidos «NGG» al lado de la secuencia complementaria a la molécula de ARN guía. Este requerimiento se mantenía para las Cas ancestrales intermedias, de 37, 137 y 200 millones de años. Mientras que las más antiguas, BCA y FCA, no parecían necesitar una secuencia PAM específica para poder cortar y aceptaban prácticamente cualquier secuencia adyacente a la secuencia reconocida por la guía ARN. Esto puede interpretarse como una evolución desde proteínas Cas sin necesidad de PAM hasta las actuales, que necesitan una PAM (distinta para cada Cas9 de cada bacteria), y tiene sentido si pensamos que la diversidad de secuencias de virus original debía ser mucho menor que la diversidad de virus actuales, por lo que la necesidad de añadir el paso de verificación con PAM debió aparecer con posterioridad.

Para poder evaluar la capacidad de las nucleasas Cas ancestrales para actuar como herramientas de edición genética se obtuvieron nuevas secuencias de ADN que codificaban las mismas secuencias de proteína, pero con un uso de codones optimizado para células humanas. Y los plásmidos resultantes, portadores de construcciones que expresaban estas secuencias de Cas ancestrales, se transfectaron a células humanas en cultivo HEK293T junto con sendas guías de ARN dirigidas contra dos genes humanos cualquiera. En este caso se escogieron los genes TYR y OCA2, cuyas mutaciones causan sendos tipos de albinismo, la enfermedad rara que investigamos en nuestro laboratorio.
El resultado no pudo ser más sorprendente. Las cuatro Cas ancestrales datadas entre 37 y 1.000 millones de años atrás, las denominadas PDCA, PCA, SCA y BCA funcionaban relativamente bien en células humanas, promoviendo la edición de los dos genes seleccionados, con eficiencias de edición genética (medidas como porcentaje de secuencias de estos dos genes con inserciones o deleciones, INDELs) que oscilaban entre un 5% y más del 80%. En general, la eficiencia decaía a medida que nos alejábamos en el tiempo. Las proteínas Cas ancestrales más «modernas» PDCA, PCA y SCA, datadas hasta 200 millones de años, son las que mejor funcionaban. Mientras que las dos más antiguas, BCA y FCA son las que registraron comparativamente menor actividad de edición. Lo cual fue especialmente cierto con la FCA, datada hace 2.600 millones de años, en la que apenas se pudo detectar un porcentaje de INDELs significativo. De nuevo un resultado que encaja con lo esperado, teniendo en cuenta que los resultados in vitro indicaban que la Cas ancestral FCA prefería cortar moléculas de ADN o ARN de cadena simple, y no doble cadena del ADN.

Más sorprendente todavía. La cicatriz que dejan estas nucleasas Cas ancestrales es muy similar a la que deja la SpCas9 de referencia. En el gráfico anterior puede verse que los nueve alelos más frecuentes encontrados tras transfectar las células humanas HEL293T, bien con la SpCas9 o con PDCA, PCA, SCA y BCA (FCA apenas general INDELs de forma significativa) son comparables, lo cual sugiere que su modo de acción (de corte de doble cadena), a pesar de los millones de años que sobre el papel las separan, no ha variado substancialmente, y que el sistema de reparación endógeno celular se encuentra con cortes de doble cadena similares que, lógicamente, también acaba reparando de forma similar, según la secuencia de ADN y su contexto.
En definitiva, en este estudio demostramos que es posible revitalizar / resucitar / reactivar secuencias ancestrales de proteínas nucleasas Cas que debieron existir en bacterias que vivieron entre 37 y 2.600 millones de años atrás. Las Cas ancestrales resucitadas muestran actividad como herramientas CRISPR de edición genética, validada funcionalmente en células humanas. También se intuye que hay margen para la optimización de estos sistemas CRISPR-Cas ancestrales, por ejemplo modificando la molécula guía del ARN para adaptarla mejor a cada una de las nucleasas resucitadas. Los siguientes pasos serán validar estas Cas ancestrales en modelos más complejos, como por ejemplo modelos animales, en ratones. Las investigaciones futuras sobre seguridad y eficacia de estos sistemas servirán para evaluar su potencial como herramientas de edición genética aplicables en biología, biotecnología o biomedicina.